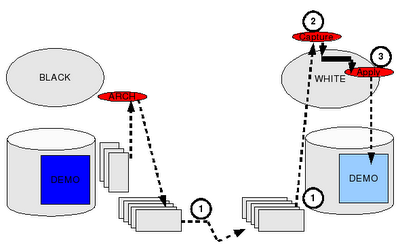
If you want to maximize your chances to mess up everything, a Streams N-Way replication configuration is probably one of the best architecture you can build... Imagine you have several copies of the same table in different places; every change made to any of the copy is pushed and applied to all the other copies. Now just think about it:
- How do you instantiate a new copy of the table without stopping everything?
- What happens when 1 destination becomes unreachable for 1 hour? 1 day? 1 week?
- What happens when you change the same row on 2 different table copies at about the same time?
- What if you replicate DDL?

This post doesn't answer any these questions. I promise I'll dig into a few of them later; instead it presents the tiniest 3-Way Streams replication configuration you can build: 3 copies of the same table in one database. The goal here is to have something to discuss further for later considerations...
So lets get into more details. In the following sections, I'll build and maintain 3 copies of the same table named T1 located in the FRANCE, USA and JAPAN schemes. In order to do it, I'll go through the steps below:
- Create the 3 schemes
- Prepare the multi-version data dictionary and the tables
- Create the Streams administrator and the Streams queue
- Create the capture process and define the capture rules
- Create the apply components
- Modify the schema of the captured change
- Instantiate the tables
- Start the capture and apply processes
- Test the replication
- Stop and suppress the Oracle Streams configuration
Note:
We've tested this post on a 11.1.0.7 Enterprise Edition Oracle database running on Linux 32bits.
Step 1: Create the 3 schemes
The very limit of this one database 3-way replication configuration consists in the fact that one table can be instantiated only once (see DBA_APPLY_INSTANTIATED_OBJECTS), when we actually instantiate each one of them 2 times; one per copy. As a result, even though we would be able to create the configuration with a limited downtime on the primary table with a 3 database system, we need to instantiate the 3 tables with the same SCN in this case. For these reason, we will create the 3 copies of the table at the beginning of this scenario and we will allow users to modify them only after we have instantiated them.
connect / as sysdbaStep 2: Prepare the multi-version data dictionary and the tables
create user france
identified by france
default tablespace users
temporary tablespace temp;
grant connect,resource to france;
create user usa
identified by usa
default tablespace users
temporary tablespace temp;
grant connect,resource to usa;
create user japan
identified by japan
default tablespace users
temporary tablespace temp;
grant connect,resource to japan;
create table france.t1(
id number primary key,
text varchar2(80));
create table usa.t1(
id number primary key,
text varchar2(80));
create table japan.t1(
id number primary key,
text varchar2(80));
insert into france.t1(id, text)
values (1,'Text 1');
insert into france.t1(id, text)
values (2,'Text 2');
insert into usa.t1
(select * from france.t1);
insert into japan.t1
(select * from france.t1);
commit;
I've already talked about the purpose of this step on order to allow the capture processes to build the LCR from the redo logs even the objects are created and dropped and to make sure there is no pending changes when the capture starts. Before we create the capture, we need to capture a copy of the data dictionary and start it in the redo logs with
DBMS_CAPTURE_ADM.BUILD:var first_scn number;And then prepare the instantiation of the 3 tables. In this later case, we did not setup supplemental logging the database level but we've added it just for the 3 tables that have primary keys; the script below prepare the objects to be instantiated:
set serveroutput on
DECLARE
scn NUMBER;
BEGIN
DBMS_CAPTURE_ADM.BUILD(
first_scn => scn);
DBMS_OUTPUT.PUT_LINE('First SCN Value = ' || scn);
:first_scn := scn;
END;
/
First SCN Value = 2260357
exec dbms_capture_adm.prepare_table_instantiation(-Step 3: Create the Streams administrator and the Streams queue
table_name=>'france.t1', supplemental_logging=>'keys');
exec dbms_capture_adm.prepare_table_instantiation(-
table_name=>'usa.t1', supplemental_logging=>'keys');
exec dbms_capture_adm.prepare_table_instantiation(-
table_name=>'japan.t1', supplemental_logging=>'keys');
Like for any other Oracle Streams configuration, we need to create a Streams Administrator and in that case one queue to be used as a link between the capture and apply processes:
connect / as sysdba
CREATE TABLESPACE streams_tbs
DATAFILE '/u01/app/oracle/oradata/BLACK/streams_tbs.dbf' size 25M
AUTOEXTEND ON MAXSIZE 256M;
CREATE USER strmadmin IDENTIFIED BY strmadmin
DEFAULT TABLESPACE streams_tbs
QUOTA UNLIMITED ON streams_tbs;
grant dba to strmadmin;
BEGIN
DBMS_STREAMS_ADM.SET_UP_QUEUE(
queue_table => 'strmadmin.streams_queue_table',
queue_name => 'strmadmin.streams_queue');
END;
/
Step 4: Create the capture process and define the capture rules
By tiniest 3-way replication configuration, I mean, I want to create as few components as possible. In this case, we have one only database, so we can create one capture only to for the 3 tables. That what we do below:
- We create the same capture for the 3 tables
- We add one inclusion rule per table to replicate the DML only
- We don't capture the changes that have a TAG because we don't want to replicate a change that is the result of an apply process
connect strmadmin/strmadminStep 5: Create the apply components
accept first_scn prompt "Enter the First SCN of the Capture: "
Enter the First SCN of the Capture: 2260357
var first_scn number;
exec :first_scn:=&&first_scn
BEGIN
DBMS_CAPTURE_ADM.CREATE_CAPTURE(
queue_name => 'strmadmin.streams_queue',
capture_name => 'streams_capture',
rule_set_name => NULL,
source_database => 'BLACK',
use_database_link => false,
first_scn => :first_scn,
logfile_assignment => 'implicit');
END;
/
col capture_name format a15
col queue_name format a13
col first_scn format 999999999999
col start_scn format 999999999999
col rule_set_name format a11
select capture_name,
queue_name,
first_scn,
start_scn,
rule_set_name
from dba_capture;
CAPTURE_NAME QUEUE_NAME FIRST_SCN START_SCN RULE_SET_N
--------------- ------------- ------------- ------------- ----------
STREAMS_CAPTURE STREAMS_QUEUE 2260357 2260357
set serveroutput on
DECLARE
type tn is varray(3) of varchar2(100);
ln tn:=tn('france.t1','usa.t1','japan.t1');
BEGIN
for i in ln.first..ln.last loop
dbms_output.put_line('Source is: '||ln(i));
DBMS_STREAMS_ADM.ADD_TABLE_RULES(
table_name => ln(i),
streams_type => 'capture',
streams_name => 'streams_capture',
queue_name => 'strmadmin.streams_queue',
include_dml => true,
include_ddl => false,
include_tagged_lcr => false,
source_database => 'BLACK',
inclusion_rule => true);
end loop;
END;
/
Source is: france.t1
Source is: usa.t1
Source is: japan.t1
set lines 120
col streams_name format a16
col streams_type format a9
col table_owner format a10
col table_name format a15
col rule_type format a8
col rule_name format a15
select STREAMS_NAME,
STREAMS_TYPE,
TABLE_OWNER,
TABLE_NAME,
RULE_TYPE,
RULE_NAME
from DBA_STREAMS_TABLE_RULES;
STREAMS_NAME STREAMS_T TABLE_OWNE TABLE_NAME RULE_TYP RULE_NAME
---------------- --------- ---------- --------------- -------- ---------
STREAMS_CAPTURE CAPTURE USA T1 DML T118
STREAMS_CAPTURE CAPTURE FRANCE T1 DML T117
STREAMS_CAPTURE CAPTURE JAPAN T1 DML T119
Opposite to the capture, we must create several apply components. That's because each change, even if it is capture only once can be applied several times. In the script below, we create one apply per target schema and we add the rules to that apply so that it applies the changes captured on the other tables:
connect strmadmin/strmadmin
set serveroutput on
DECLARE
type t_n is varray(3) of varchar2(100);
l_n t_n:=t_n('france','usa','japan');
BEGIN
for i in l_n.first..l_n.last loop
for j in l_n.first..l_n.last loop
if (l_n(i)!=l_n(j)) then
dbms_output.put_line('APPLY '||l_n(i)||'_apply'||
' applies '||l_n(j)||'.t1');
DBMS_STREAMS_ADM.ADD_TABLE_RULES(
table_name => l_n(j)||'.t1',
streams_type => 'apply',
streams_name => l_n(i)||'_apply',
queue_name => 'strmadmin.streams_queue',
include_dml => true,
include_ddl => false,
include_tagged_lcr => false,
source_database => 'BLACK',
inclusion_rule => true);
end if;
end loop;
end loop;
END;
/
APPLY france_apply applies usa.t1
APPLY france_apply applies japan.t1
APPLY usa_apply applies france.t1
APPLY usa_apply applies japan.t1
APPLY japan_apply applies france.t1
APPLY japan_apply applies usa.t1
col apply_name format a13
col queue_name format a13
col rule_set_name format a11
col tag format a4
select apply_name,
queue_name,
rule_set_name,
status,
message_delivery_mode,
apply_tag tag
from dba_apply;
APPLY_NAME QUEUE_NAME RULE_SET_NA STATUS MESSAGE_DE TAG
------------- ------------- ----------- -------- ---------- ----
JAPAN_APPLY STREAMS_QUEUE RULESET$_27 ENABLED CAPTURED 00
USA_APPLY STREAMS_QUEUE RULESET$_24 ENABLED CAPTURED 00
FRANCE_APPLY STREAMS_QUEUE RULESET$_21 ENABLED CAPTURED 00
Step 6: Modify the schema of the captured change
If the database is the same for the 3 tables, the schema name differ. As a result, a change to the
USA.T1 table must be applied to FRANCE.T1 and JAPAN.T1. The script below add some transformation rules to change the schema name of each one of the LCR; it does that transformation on the apply side:connect strmadmin/strmadminStep 7: Instantiate the tables
select rule_owner
, rule_name
, streams_type
, streams_name
, table_name
, table_owner
from dba_streams_table_rules
where streams_type='APPLY';
set serveroutput on
DECLARE
type t_n is varray(3) of varchar2(100);
l_n t_n:=t_n('france','usa','japan');
v_rulename varchar2(30);
BEGIN
for i in l_n.first..l_n.last loop
for j in l_n.first..l_n.last loop
if (l_n(i)!=l_n(j)) then
dbms_output.put_line('APPLY: '||
l_n(i)||'_apply for CAPTURE OF '||
l_n(j)||'.t1');
select rule_name
into v_rulename
from dba_streams_table_rules
where streams_type='APPLY'
and streams_name=upper(l_n(i))||'_APPLY'
and table_name='T1'
and table_owner=upper(l_n(j));
dbms_output.put_line(rpad(' ',10)||'=>'||v_rulename);
dbms_streams_adm.rename_schema(
rule_name => v_rulename,
from_schema_name => l_n(j),
to_schema_name => l_n(i),
step_number => 0,
operation => 'add');
end if;
end loop;
end loop;
END;
/
col rule_name format A6
col from_schema_name format a6
col to_schema_name format a12
select rule_name,
transform_type,
from_schema_name,
to_schema_name,
declarative_type
from dba_streams_transformations;
RULE_N TRANSFORM_TYPE FROM_S TO_SCHEMA_NA DECLARATIVE_T
------ -------------------------- ------ ------------ -------------
T120 DECLARATIVE TRANSFORMATION USA FRANCE RENAME SCHEMA
T123 DECLARATIVE TRANSFORMATION FRANCE USA RENAME SCHEMA
T122 DECLARATIVE TRANSFORMATION JAPAN FRANCE RENAME SCHEMA
T125 DECLARATIVE TRANSFORMATION JAPAN USA RENAME SCHEMA
T126 DECLARATIVE TRANSFORMATION FRANCE JAPAN RENAME SCHEMA
T128 DECLARATIVE TRANSFORMATION USA JAPAN RENAME SCHEMA
Actually, because of what I said in the first step of this post, the tables are already instantiated. However, we need to set provide a SCN to the apply component that is higher than the SCN of the prepare instantiation so that the process can know which changes to apply; we'll just get the current SCN of the database:
connect / as sysdbaAnd use it with the
col apply_scn format 999999999999
select dbms_flashback.get_system_change_number apply_scn
from dual;
APPLY_SCN
---------
2269379
accept instantiation_scn prompt "Enter the Instantiation: "
Enter the Instantiation: 2269379
dbms_apply_adm.set_table_instantiation_scn procedure for the 3 "source" tables:DECLARE
type t_n is varray(3) of varchar2(100);
l_n t_n:=t_n('france','usa','japan');
BEGIN
for i in l_n.first..l_n.last loop
dbms_apply_adm.set_table_instantiation_scn(
source_object_name => l_n(i)||'.t1',
source_database_name => 'BLACK',
instantiation_scn => &&instantiation_scn);
end loop;
end;
/
col SOURCE_DATABASE format a6
col OBJECT format a10
col INSTANTIATION_SCN format 999999999999
SOURCE OBJECT INSTANTIATION_SCN
------ ---------- -----------------
BLACK FRANCE.T1 2269379
BLACK USA.T1 2269379
BLACK JAPAN.T1 2269379
Step 8: Start the capture and apply processes
We are all set, we can let users access the tables and we can start the different processes :
exec dbms_capture_adm.start_capture('streams_capture');
exec dbms_apply_adm.start_apply('usa_apply');
exec dbms_apply_adm.start_apply('france_apply');
exec dbms_apply_adm.start_apply('japan_apply');
Step 9: Test the replicationThat's probably the most enjoyable moment... you can make sure that the replication is working as it should:
insert into france.t1(id, text)And like me, you can probably not resist to see what happens when what should be avoided happens in a N-Way Replication like this one; We'll create a uniqueness conflit:
values (3,'Text 3');
commit;
pause
col id format 99
col text format a6
select id,
text
from usa.t1;
ID TEXT
--- ------
1 Text 1
2 Text 2
3 Text 3
select id,
text
from japan.t1;
ID TEXT
--- ------
1 Text 1
2 Text 2
3 Text 3
insert into usa.t1(id, text)
values (4,'Text 4');
insert into japan.t1(id, text)
values (5,'Text 5');
commit;
select id,
text
from france.t1
order by 1;
ID TEXT
-- ------
1 Text 1
2 Text 2
3 Text 3
4 Text 4
5 Text 5
insert into usa.t1(id, text)
values (6,'Text 6 Usa');
insert into japan.t1(id, text)
values (6,'Text 6 Japan');
commit;
select id,
text
from france.t1
order by 1;
ID TEXT
-- ------
1 Text 1
2 Text 2
3 Text 3
4 Text 4
5 Text 5
col id format 99
col text format a12
select id,
text
from usa.t1
order by 1;
ID TEXT
--- ----------
1 Text 1
2 Text 2
3 Text 3
4 Text 4
5 Text 5
6 Text 6 Usa
select id,
text
from japan.t1
order by 1;
ID TEXT
--- ------------
1 Text 1
2 Text 2
3 Text 3
4 Text 4
5 Text 5
6 Text 6 Japan
col error_message format a60
select APPLY_NAME, ERROR_MESSAGE
from dba_apply;
APPLY_NAME ERROR_MESSAGE
------------- --------------------------------------------------
JAPAN_APPLY ORA-26714: User error encountered while applying
USA_APPLY ORA-26714: User error encountered while applying
FRANCE_APPLY ORA-26714: User error encountered while applying
select APPLY_NAME, ERROR_MESSAGE
from dba_apply_error;
APPLY_NAME ERROR_MESSAGE
------------- ------------------------------------------------------------
FRANCE_APPLY ORA-00001: unique constraint (FRANCE.SYS_C004474) violated
USA_APPLY ORA-00001: unique constraint (USA.SYS_C004475) violated
JAPAN_APPLY ORA-00001: unique constraint (JAPAN.SYS_C004476) violated
Note:Step 10: Stop and suppress the Oracle Streams configuration
On 3 databases the result would be different on theFRANCE.T1.Even if the change had been made from the same 2PC transaction it would have been considered different.
This last step cleans up the configuration; this way, you can restart it as many times as you want:
connect / as sysdba
exec dbms_capture_adm.stop_capture('streams_capture');
exec dbms_apply_adm.stop_apply('usa_apply');
exec dbms_apply_adm.stop_apply('france_apply');
exec dbms_apply_adm.stop_apply('japan_apply');
exec dbms_apply_adm.delete_all_errors('usa_apply')
exec dbms_apply_adm.delete_all_errors('france_apply')
exec dbms_apply_adm.delete_all_errors('japan_apply')
exec dbms_capture_adm.drop_capture('streams_capture');
exec dbms_apply_adm.drop_apply('usa_apply');
exec dbms_apply_adm.drop_apply('france_apply');
exec dbms_apply_adm.drop_apply('japan_apply');
DECLARE
type t_n is varray(3) of varchar2(100);
l_n t_n:=t_n('france','usa','japan');
BEGIN
for i in l_n.first..l_n.last loop
dbms_apply_adm.set_table_instantiation_scn(
source_object_name => l_n(i)||'.t1',
source_database_name => 'BLACK',
instantiation_scn => null);
end loop;
end;
/
exec dbms_streams_adm.remove_queue('strmadmin.streams_queue',true,true);
drop user strmadmin cascade;
drop tablespace streams_tbs
including contents and datafiles;
drop user france cascade;
drop user usa cascade;
drop user japan cascade;
Read more...