Oracle Streams downstream capture is probably one of most commonly used Streams configuration, whether its for a long time replication or for a short period of time like during a database upgrade. The limited impact on the source database advocates for that configuration; That's because, it only requires to add supplemental logging and to capture the dictionary from it the primary database.
On the other hand, Oracle Recovery Manager, or RMAN, is one of the most common way to clone a database and it can easily manage several hundreds of Gigabytes, or more. It's probably one of the number one tools for most Oracle Database Administrator.
This post shows a simple setup of Streams Real Time Downstream Capture instantiated with the help of RMAN; like in the first post of this blog "
", we will focus on keeping everything simple and we'll use many shortcuts to get to the result. However, you should be able fill the gap with your needs pretty easily and you'll get all the details in the documentation. Regarding that specific configuration, you can start with
.
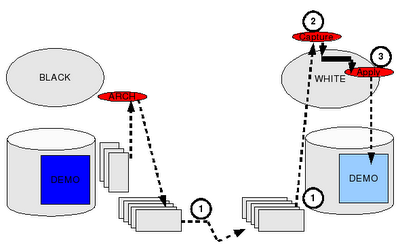
Lets start... We'll build the configuration shown in the graphic below:
Note
The above configuration requires Oracle Database Enterprise Edition
We'll assume we have already have a database and its instance; they are both named BLACK in what follow. We'll get into all the steps related to the demo setup, from the creation of the source schema to the testing of the working configuration; here are the related sections:
2 Words About the Source Database and its schema
The source database and its instance are both named BLACK. The script below creates a DEMO schema with 2 tables T1 and T2 that have primary keys and which are fully supported by Streams:
connect / as sysdba
create user demo
identified by demo
default tablespace users
temporary tablespace temp;
grant connect, resource to demo;
connect demo/demo
create table t1 (
id number primary key,
lib varchar2(10));
create table t2 (
id number primary key,
lib varchar2(10));
insert into demo.t1
values (1,'data 1');
insert into demo.t1
values (2,'data 2');
insert into demo.t2
values (1,'data 1');
commit;
Note
To ease the work, we assume there is no unsupported type in the application schema (see DBA_STREAMS_UNSUPPORTED) and all the tables have a primary a unique key.
Configure Database Logging and Prepare the Multi-Version Data Dictionary
For more details about the requirements of a Streams Source Database, you can refer to the related section of the 1st post of this blog. To make it short, you need the database to be in archivelog mode and to configure supplemental logging:
connect / as sysdba
alter database add supplemental log
data (primary key, unique index) columns;
select LOG_MODE,
SUPPLEMENTAL_LOG_DATA_MIN,
SUPPLEMENTAL_LOG_DATA_PK,
SUPPLEMENTAL_LOG_DATA_UI
from v$database;
LOG_MODE SUPPLEME SUP SUP
------------ -------- --- ---
ARCHIVELOG IMPLICIT YES YES
You also need to a copy of the data dictionary from the source to the destination database. To do it, we need to run DBMS_CAPTURE_ADM.BUILD as below:
var first_scn number;
set serveroutput on
DECLARE
scn NUMBER;
BEGIN
DBMS_CAPTURE_ADM.BUILD(
first_scn => scn);
DBMS_OUTPUT.PUT_LINE('First SCN Value = ' || scn);
:first_scn := scn;
END;
/
First SCN Value = 319193
It is important to keep track of the SCN returned by DBMS_CAPTURE_ADM.BUILD. You'll use that SCN as the first SCN of the capture processes so that the meta data from the source database can be pushed and kept in the destination MVDD. Note that the last command captures the minimum to add to the MVDD and you have to add some additional definition for the objects you want to replicate. You should use one of the prepare_xxxx_instantiation procedure of the dbms_capture_adm package to add the related definitions in the redologs:
exec dbms_capture_adm.prepare_table_instantiation(-
table_name=>'demo.t1');
exec dbms_capture_adm.prepare_table_instantiation(-
table_name=>'demo.t2');
Duplicate you database with RMAN
You can use the method of your choice to instanciate the data on the destination database. What matters is that (1) you know the SCN of the table copies and (2) that SCN called the instanciation SCN is after the first SCN returned by DBMS_CAPTURE_ADM.BUILD. In what follows, we'll use Recovery Manager to get to that; we'll fully leverage the 11g new DUPLICATE FROM ACTIVE DATABASE command.
Note
In that example, we'll duplicate BLACK to build a new database named WHITE on the same server; Because the 2 databases will run on the same server, we'll rename the directories /.../BLACK into /.../WHITE.
To duplicate the database, we can run the following operations:
- Configure the service for the new Instance; On Linux, the command looks like below:
echo "WHITE:$ORACLE_HOME:N" >>/etc/oratab
- Setup the environment for the new instance
. oraenv
WHITE
- Create a password file with the same password than for the
BLACK instance:
cd $ORACLE_HOME
orapwd file=orapwWHITE password=change_on_install ignorecase=Y
- Statically register the WHITE
instance in its local listener, via the listener.ora file. It allows to connect to WHITE with a SYSDBA user from a remote location even when the instance is down.
cd $ORACLE_HOME/network/admin
$ grep -A 6 SID_LIST_LISTENER listener.ora
SID_LIST_LISTENER =
(SID_LIST =
(SID_DESC =
(ORACLE_HOME = /u01/app/oracle/product/11.1.0/db_1)
(SID_NAME = WHITE)
)
)
lsnrctl reload listener
- Create an alias for the 2 instances in the
tnsnames.ora file:
cd $ORACLE_HOME/network/admin
$ cat tnsnames.ora
BLACK =
(DESCRIPTION =
(ADDRESS_LIST =
(ADDRESS=(PROTOCOL=TCP)(HOST=localhost)(PORT=1521))
)
(CONNECT_DATA= (SID=BLACK)
)
)
WHITE =
(DESCRIPTION =
(ADDRESS_LIST =
(ADDRESS=(PROTOCOL=TCP)(HOST=localhost)(PORT=1521))
)
(CONNECT_DATA= (SID=WHITE)
)
)
- Create an init.ora file to start the new instance. Note that you can do it with 4 parameters only (even 3 if you use the 11g
memory_target parameter); The spfile will be rebuilt from the BLACK one during the DUPLICATE operation anyway:
cd $ORACLE_HOME/dbs
echo "db_name=WHITE" >initWHITE.ora
echo "pga_aggregate_target=160M" >>initWHITE.ora
echo "processes=100" >>initWHITE.ora
echo "sga_target=250M" >>initWHITE.ora
- If the source database uses some directories that are not managed automatically by OMF or ADR, you'll have to create the corresponding directories for the new database
# Corresponding destination for non-OMF datafiles
mkdir -p /u01/app/oracle/oradata/WHITE
# Corresponding destination for archivelogs
mkdir -p /u01/app/oracle/oradata/WHITE/archivelogs
# Audit File Destination
mkdir -p $ORACLE_BASE/admin/WHITE/adump
- Connect to both source and destination database with RMAN:
$ORACLE_HOME/bin/rman
connect target sys@black
database Password:
connected to target database: BLACK (DBID=361377223)
connect auxiliary sys@white
auxiliary database Password:
connected to auxiliary database (not started)
- Start the
WHITE instance in nomount mode:
startup auxiliary nomount;
- Run the
DUPLICATE command:
DUPLICATE TARGET DATABASE
TO WHITE
FROM ACTIVE DATABASE
DB_FILE_NAME_CONVERT 'BLACK','WHITE'
SPFILE
PARAMETER_VALUE_CONVERT 'BLACK','WHITE'
SET PGA_AGGREGATE_TARGET = '150M'
SET SGA_TARGET = '250M'
SET LOG_FILE_NAME_CONVERT 'BLACK','WHITE';
- exit RMAN, the
DUPLICATE operation is done!
exit;
Create the Streams Administrator and the Streams Queue
We'll create the Streams Administrator and the Streams Queue on the WHITE database; for a more detailed explanation, refer to the corresponding section of my previous post: . oraenv
WHITE
sqlplus / as sysdba
CREATE TABLESPACE streams_tbs
DATAFILE '/u01/app/oracle/oradata/WHITE/streams_tbs01.dbf'
SIZE 25M AUTOEXTEND ON MAXSIZE 256M;
CREATE USER strmadmin IDENTIFIED BY strmadmin
DEFAULT TABLESPACE streams_tbs
QUOTA UNLIMITED ON streams_tbs;
grant dba to strmadmin;
BEGIN
DBMS_STREAMS_ADM.SET_UP_QUEUE(
queue_table => 'strmadmin.streams_queue_table',
queue_name => 'strmadmin.streams_queue');
END;
/
exit;
Note
In the case of a downsteam capture, there is no need to create a Streams Administrator on the source database. There is no need either to create a database link from or to the source database and the global_names parameter doesn't have to be set to true.
Setup the Log Transport Service for Downstream Capture
To allow the redo logs to be shipped from BLACK to WHITE:
- Create standby redo logs of the size of the
BLACK database on WHITE. - Change the
log_archive_dest_n parameters of the BLACK instance so that the logs are shipped in asynchronous mode to WHITE.
To start, we'll check the size of the redolog files on BLACK:
. oraenv
BLACK
sqlplus / as sysdba
select thread#, sequence#, bytes
from v$log
order by 1,2;
THREAD# SEQUENCE# BYTES
------- --------- ----------
1 17 52428800
1 18 52428800
1 19 52428800
exit;
Then we'll create standby redologs of the same size on WHITE:. oraenv
WHITE
sqlplus / as sysdba
alter database add standby logfile thread 1 group 21
('/u01/app/oracle/oradata/WHITE/redo21_1.log') SIZE 52428800;
alter database add standby logfile thread 1 group 22
('/u01/app/oracle/oradata/WHITE/redo22_1.log') SIZE 52428800;
alter database add standby logfile thread 1 group 23
('/u01/app/oracle/oradata/WHITE/redo23_1.log') SIZE 52428800;
exit;
Once the standby redologs created, we can setup the log transport service on the BLACK instance:
. oraenv
BLACK
sqlplus / as sysdba
alter system set log_archive_dest_2=
'service=WHITE lgwr async noregister valid_for=(online_logfiles,all_roles) db_unique_name=WHITE';
alter system set log_archive_config=
'dg_config=(BLACK,WHITE)';
alter system set log_archive_dest_state_2=enable;
exit
. oraenv
WHITE
sqlplus / as sysdba
alter system set log_archive_config=
'dg_config=(BLACK,WHITE)';
exit
Note:
In the case of Real-Time Capture, redo logs are shipped by the LNS process to the RFS processes. The logs data are then stored in the standby redo logs files. The ARCH processes of the destination instance archive the standby redo logs; As a consequence you should not use the template clause.
Create the Downstream Capture
The downstream capture creation is exactly like the capture creation on the source database. The only difference is the source database name that, in this case, is different from the actual capturing database:
connect strmadmin/strmadmin
BEGIN
DBMS_CAPTURE_ADM.CREATE_CAPTURE(
queue_name => 'strmadmin.streams_queue',
capture_name => 'streams_capture',
rule_set_name => NULL,
source_database => 'BLACK',
use_database_link => false,
first_scn => 319193,
logfile_assignment => 'implicit');
END;
/
Once the capture created, we'll set its downstream_real_time_mine property to Y:
BEGIN
DBMS_CAPTURE_ADM.SET_PARAMETER(
capture_name => 'streams_capture',
parameter => 'downstream_real_time_mine',
value => 'Y');
END;
/
We can eventually add the capture rules:
connect strmadmin/strmadmin
BEGIN
DBMS_STREAMS_ADM.ADD_TABLE_RULES(
table_name => 'demo.t1',
streams_type => 'capture',
streams_name => 'streams_capture',
queue_name => 'strmadmin.streams_queue',
include_dml => true,
include_ddl => true,
include_tagged_lcr => false,
source_database => 'BLACK',
inclusion_rule => true);
END;
/
BEGIN
DBMS_STREAMS_ADM.ADD_TABLE_RULES(
table_name => 'demo.t2',
streams_type => 'capture',
streams_name => 'streams_capture',
queue_name => 'strmadmin.streams_queue',
include_dml => true,
include_ddl => true,
include_tagged_lcr => false,
source_database => 'BLACK',
inclusion_rule => true);
END;
/
Specify the Instanciation SCN and Create the Apply
We need to specify the SCN of the tables so that the Apply knows what transaction it should start to apply. In the case of the RMAN duplicate command, that's the SCN right before the open resetlogs:
select INCARNATION#,RESETLOGS_TIME,RESETLOGS_CHANGE#
from v$database_incarnation
order by 1;
INCARNATION# RESETLOGS RESETLOGS_CHANGE#
------------ --------- -----------------
1 26-JAN-09 1
2 03-FEB-09 329645
begin
dbms_apply_adm.set_table_instantiation_scn(
source_object_name => 'demo.t1',
source_database_name => 'BLACK',
instantiation_scn => 329644);
end;
/
begin
dbms_apply_adm.set_table_instantiation_scn(
source_object_name => 'demo.t2',
source_database_name => 'BLACK',
instantiation_scn => 329644);
end;
/
col SOURCE_DATABASE format a6
col OBJECT format a10
col INSTANTIATION_SCN format 999999999999
select source_database,
source_object_owner||'.'||source_object_name object,
instantiation_scn
from dba_apply_instantiated_objects;
SOURCE OBJECT INSTANTIATION_SCN
------ ---------- -----------------
BLACK DEMO.T1 329644
BLACK DEMO.T2 329644
We can create the Apply like below. In that case, creating the rules implicitly create the associated Apply if it doesn't exist:
-- Create the Apply and add the DEMO.T1 table
BEGIN
DBMS_STREAMS_ADM.ADD_TABLE_RULES(
table_name => 'demo.t1',
streams_type => 'apply',
streams_name => 'streams_apply',
queue_name => 'strmadmin.streams_queue',
include_dml => true,
include_ddl => true,
include_tagged_lcr => false,
source_database => 'BLACK',
inclusion_rule => true);
END;
/
BEGIN
DBMS_STREAMS_ADM.ADD_TABLE_RULES(
table_name => 'demo.t2',
streams_type => 'apply',
streams_name => 'streams_apply',
queue_name => 'strmadmin.streams_queue',
include_dml => true,
include_ddl => true,
include_tagged_lcr => false,
source_database => 'BLACK',
inclusion_rule => true);
END;
/
The configuration is over...
Start And Monitor Oracle Streams
Once Streams Capture and Apply created, start both of them:
exec dbms_capture_adm.start_capture('streams_capture');
exec dbms_apply_adm.start_apply('streams_apply');
Before we test changes on the source database are replicated as expected to the destination server, we can check the status of the components involved, we'll start by checking the status of the Log Transport Service on the BLACK instance and manage any error:
show parameter log_archive_dest_2
show parameter log_archive_dest_state_2
alter session set nls_date_format='DD-MON-YYYY HH24:MI:SS';
col dest_id format 99
col timestamp format a20
col message format a90 wor wra
set pages 1000
set lines 120
select dest_id,
timestamp,
message
from v$dataguard_status
order by timestamp;
select process,
pid,
status,
sequence#,
thread#
from v$managed_standby;
You can check that the files sent by BLACK are registered as expected on WHITE
select process,
status,
client_process,
sequence#,
thread#
from v$managed_standby;
set lines 120
set pages 1000
col consumer_name format a15
col name format a65 wor wra
col source format a6
col t# format 99
col seq# format 9999999
select consumer_name ,
source_database source,
thread# t#,
sequence# seq#,
first_scn,
name,
purgeable
from dba_registered_archived_log
order by source_database, first_scn;
You can also check the status of the standby logs on WHITE
set lines 120
set pages 1000
col dbid format 999999999999999
col bytes format 999,999,999,999
col first_change# format 999999999999999
col sequence# format 9999999
select dbid,
sequence#,
bytes,
status,
first_change#
from v$standby_log;
The streams capture should be running without any error on WHITE
set lines 120
set pages 1000
col capture_name format a15
col status format a7
col source format a6
col error_message format a85 wor wra
select capture_name,
status,
source_database source,
error_message
from dba_capture;
set lines 120
set pages 1000
col capture_name format a15
col state format a50 wor wra
col sysdate format a20
col capture_time format a20
col total_messg format 99999999999
col apply_name format a15
alter session set nls_date_format='DD-MON-YYYY HH24:MI:SS';
select capture_name,
state,
capture_time,
total_messages_created total_messg,
apply_name
from v$streams_capture;
The apply should be running without any error on WHITE
alter session set nls_date_format='DD-MON-YYYY HH24:MI:SS';
set lines 120
set pages 1000
col apply_name format a15
col status format a7
col status_change_time format a20
col error_message format a60 wor wra
select apply_name,
status,
status_change_time,
error_message
from dba_apply;
set lines 120
set pages 1000
col apply_name format a15
col source_database format a7
col sysdate format a20
col apply_time format a20
col applied_message_create_time format a20
select apply_name,
source_database,
sysdate,
apply_time,
applied_message_create_time
from dba_apply_progress;
If there is any remaining error, you'll have to correct it ;-).
Test the Replication
Testing the replication is pretty easy, connect to the BLACK database and run some DML and DDL commands:
sqlplus demo/demo@BLACK
insert into t1
values (3,'data 3');
commit;
select * from t1;
ID LIB
-- ------
3 data 3
1 data 1
2 data 2
alter table t2 add (new_column number);
update t2 set new_column=2;
commit;
select * from t2;
ID LIB NEW_COLUMN
-- ------ ----------
1 data 1 2
exit;
Once the changes performed, you can check they are applied to the destination:
sqlplus demo/demo@WHITE
select * from t1;
ID LIB
-- ------
3 data 3
1 data 1
2 data 2
select * from t2;
ID LIB NEW_COLUMN
-- ------ ----------
1 data 1 2
exit;
You see how easy it is!
Other Considerations
What next? Because simplest part of the story has actually finished here!
We can easily imagine you'll use Streams Downstream Capture to upgrade a database with a new Release or Patch Set. If that's the case, consider using the dynamic service registration to make the application connect to your new target seamlessly. Obviously I didn't say how to deal with non-supported types or operations. Or eventually, how to build a really advanced rollback scenario. That's a totally different story... in a totally different dimension.
Concerning this hands-on, we'll finish it by cleaning up our environment, i.e. disable the Log Transport Service, remove the supplemental logging from BLACK, drop the WHITE database and its instance and drop the DEMO schema; The script below shows how to deal with those operations:
. oraenv
BLACK
sqlplus / as sysdba
alter system reset log_archive_dest_2;
alter system reset log_archive_dest_state_2;
alter system reset log_archive_config;
alter system set log_archive_dest_2='' scope=memory;
alter system set log_archive_config='' scope=memory;
alter database drop supplemental log
data (primary key, unique index) columns;
select SUPPLEMENTAL_LOG_DATA_MIN,
SUPPLEMENTAL_LOG_DATA_PK,
SUPPLEMENTAL_LOG_DATA_UI
from gv$database;
drop user demo cascade;
exit;
. oraenv
WHITE
$ORACLE_HOME/bin/rman target /
startup force mount
sql 'alter system enable restricted session';
drop database including backups;
exit;
###################################
# Delete Remaining Database Files #
###################################
# Delete the entries in $ORACLE_HOME/dbs
rm -f $ORACLE_HOME/dbs/*WHITE*
# Delete the Streams Registered Archived Logs
# (RMAN doesn't do it)
rm -f /u01/app/oracle/oradata/WHITE/archivelogs/*
# Delete the database Directories
rm -rf $ORACLE_BASE/oradata/WHITE
rm -rf $ORACLE_BASE/admin/WHITE
rm -rf $ORACLE_BASE/diag/rdbms/white
# Delete the WHITE instance from /etc/oratab
ed /etc/oratab <<EOF
/^WHITE/d
wq
EOF
# Remove the entries from the network configuration
# like tnsnames.ora and listener.ora manually
vi $ORACLE_BASE/network/admin/tnsnames.ora
vi $ORACLE_BASE/network/admin/listener.ora
lsnrctl reload LISTENER
Leave your comments if you find this post useful or confusing. Let me know if you find any typos!